Common sampling protocol
Before each field season, the project group prepares and distributes a common field protocol to partners which describes how to program loggers, attach them to birds and download data from the loggers. It describes additional sampling like biometrics, breeding success and sampling for related projects like Arctox (ARCTOX website), which collects feathers and blood for analysis of stable isotopes and pollution. It also provides suggestions for an experimental setup if partners want to take part in studies of logger effects.
Standardized meta data collection
Field notes are encouraged to be shared with the project group so it can be made available through the SEATRACK database. Field notes include any information relevant when capturing a bird or information about loggers programmed, deployed and retrieved. Some of this information is mandatory to be able to analyse the logger data. Mandatory data may be the individual id of the bird carrying the logger, date and place of instrumentation, and how logger was programmed. Partners are encouraged to fill in field notes using a standardized metadata template distributed before every field season.
Centralized database and file archive
After fieldwork, field notes and logger data is stored centrally with the SEATRACK project group (see Figure 1). All files get named following a naming convention to be searchable and archived. Data is then further error checked, standardized, and whenever feasible normalized, and imported into the SEATRACK database. Here, data is stored within large tables which are interlinked. The data collected are the shared property of SEATRACK and partners, and the data is tagged with the name of the partner as “data responsible”.
The project group is responsible for producing a positional dataset from the ambient light data recorded by geolocators each year. A brief description of how this is done can be found in the next pargraph Standardized data processing. These positions are used in producing maps in the distribution app and are one of the main deliverables from SEATRACK.
For six pelagic species, an Informed Random Movement Algorithm (IRMA) has been established to fill non-random gaps in the positional dataset. Its detailed description can be found here: IRMA. The six species are Atlantic puffin, Brünnich’s guillemot/thick-billed murre, common guillemot/common murre, little auk (dovkie), black-legged kittiwake and northern fulmar.
Based on the complete positional IRMA dataset for six species, we use Bayesian Additive Regression Trees (BART) to model monthly abundance of seabirds across the North Atlantic as individuals per km2 for each species and breeding population (NAS). The NAS dataset is displayed in the abundance app and is an important main deliverable from SEATRACK as a mapping tool for environmental impact assessments.
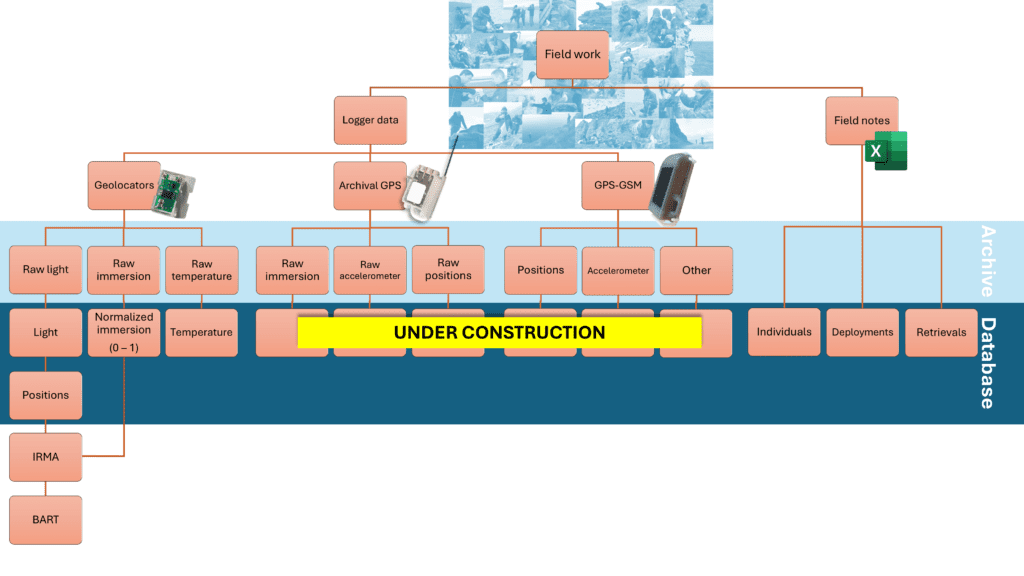
Standardized data processing
GLS loggers – from light to locations
Geolocator data can produce on average two positions each date. Geolocators primarily record ambient light, which in turn can be used to time the occurrence of night and daytime. From this, timing of noon and midnight can be used to estimate longitudinal positions, and the approximate length of each day or night can be used to produce latitudinal positions. The principle of light-derived geolocation face three common problems: 1) any obstacle preventing sunlight reaching the loggers’ light sensor reduce accuracy, 2) polar night and midnight sun will preclude location estimates, 3) equinox preclude reliable estimation of latitudes for weeks close to equinox due to a diminishing gradient in daylengths between the North and South Pole. In addition, light sensors might be different in their sensitivity to light.
There are several tools available for estimating locations from ambient light-level data. In SEATRACK we have developed a procedure in R for estimating locations based on comprehensive twilight and positional filtering to abate problem 1. We use two thresholds of light to reduce problem 2, thereby enabling more locations estimates during poor diminishing daylight (winter, low threshold) and bright light conditions (summer, high threshold). Since the effect of equinox vary as a function of both time and latitude, we use a dynamic way of tagging unreliable latitude estimates to limit the extent of problem 3, meaning less latitudes will be tagged in arctic/Antarctic regions. To account for difference in light sensor sensitivity we do a manual calibration of the light data to achieve reliable estimates.
Detailed method description
A detailed method description is currently under writing, but an example of running data and outputs of the R script is available and an outdated description which explains the main principles (main principles description).
Link to a github repository will be added soon.
GPS loggers
Any GPS data available from the SEATRACK database will have been standardized and filtered to remove erroneous datapoints.





